A Basic Approach to the Expectation-Maximization Algorithm
In machine learning, the EM algorithm is a fundamental tool for unsupervised learning. It is the core mechanism behind clustering algorithms like Gaussian Mixture Models (GMMs) and is used in various fields, from natural language processing to computer vision, for problems involving missing data.
A Basic Approach to the Expectation-Maximization Algorithm
Two Biased Coins
Author: Ali Nawaf
Date: September 5, 2025
Introduction
The Expectation-Maximization (EM) algorithm is an iterative method for finding maximum likelihood estimates of parameters in statistical models that depend on unobserved, or latent, variables. It alternates between performing an expectation (E) step, which creates a function for the expectation of the log-likelihood evaluated using the current estimate for the parameters, and a maximization (M) step, which computes parameters maximizing the expected log-likelihood found in the E-step. These new parameters are then used in the subsequent E-step.
In machine learning, the EM algorithm is a fundamental tool for unsupervised learning. It is the core mechanism behind clustering algorithms like Gaussian Mixture Models (GMMs) and is used in various fields, from natural language processing to computer vision, for problems involving missing data.
Problem Definition
We consider a simple experiment involving two biased coins, Coin A and Coin B. The true, hidden probability of each coin landing on Heads is:
- Coin A:
- Coin B:
For any given flip, both coins are equally likely to be chosen, meaning the probability of selecting either coin is . Our goal is to estimate the hidden biases and using only a sequence of observed outcomes (Heads or Tails), without knowing which coin was used for which flip.
Mathematical Formulation
The algorithm iterates between an E-step and an M-step to converge on the most likely parameters. Let our observed data be , where for Heads and for Tails.
E-Step: Calculating Responsibilities
In the E-step, we calculate the posterior probability, or "responsibility," that each coin has for each observation, given our current parameter estimates .
The responsibility of Coin A for observation , denoted , is calculated as:
Given our assumption that , this simplifies to:
Where:
- .
The responsibility for Coin B is simply:
M-Step: Maximizing the Likelihood
In the M-step, we use the responsibilities to calculate new, improved estimates for our parameters.
For Coin A, the update is:
For Coin B, the update is:
Example: First Iteration
Let's assume an initial guess of and .
- For an observation of Heads ():
- For an observation of Tails ():
If our 100-flip dataset has 58 Heads and 42 Tails, the soft counts are:
- Total Heads A =
- Total Tails A =
- Total Heads B =
- Total Tails B =
The new parameter estimates after one iteration are:
Final Output
After running the algorithm for 100 iterations with a good initial guess (e.g., ) on the provided 100-flip dataset, the parameters converge to values that are very close to the actual probabilities present in the random sample.
The final estimated parameters were:
- Final :
- Final :
Limitations of this Method
The most significant limitation of the EM algorithm is its sensitivity to initial values. The algorithm is a "hill-climbing" method that seeks to find the peak of the log-likelihood landscape. If this landscape has multiple peaks (a global maximum and several local maxima), the algorithm is only guaranteed to find the top of the peak it starts nearest to.
A poor initial guess can cause the algorithm to converge to a suboptimal local maximum, yielding incorrect parameter estimates. This is illustrated in the figure below, where a good initial guess finds the correct solution, while a bad guess gets stuck in a poor, local maximum.
To mitigate this, the standard practice is to run the algorithm multiple times with different random starting points and choose the result that yields the highest final log-likelihood.
| Good Run |
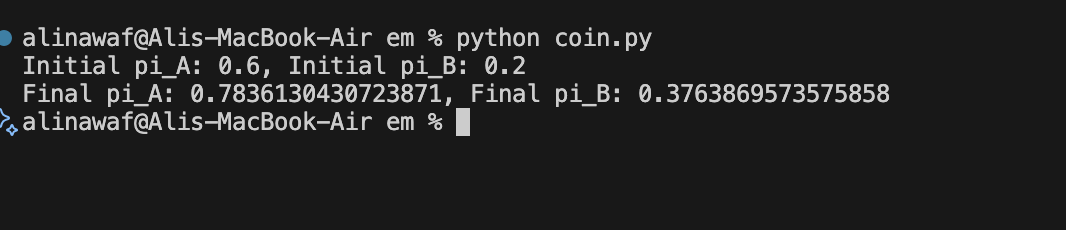
| Bad Run |
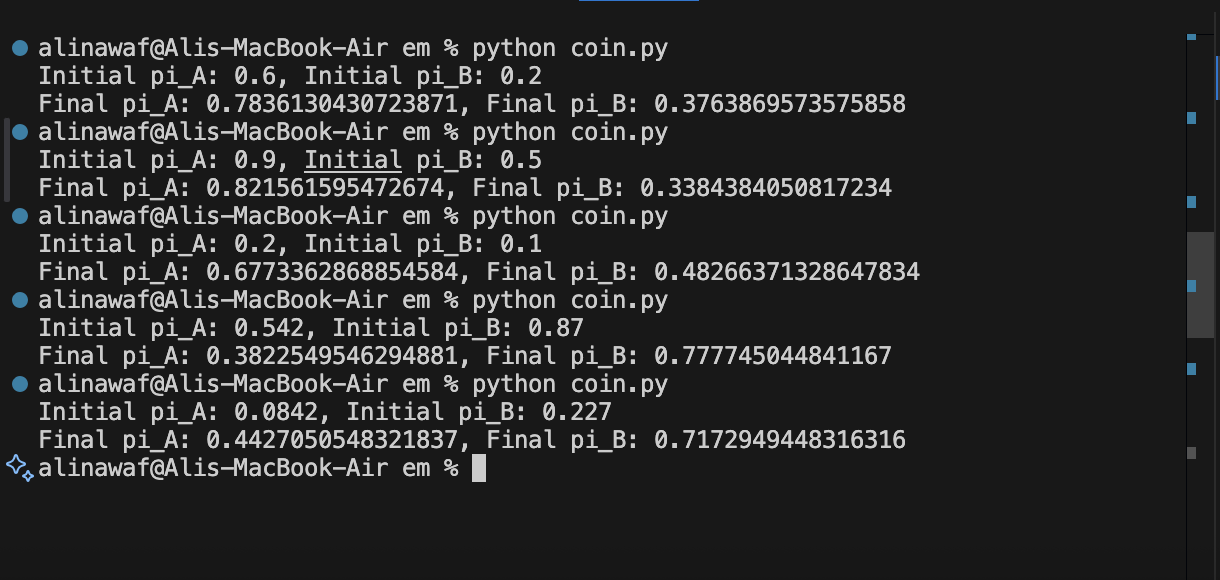
| Figure 1: Convergence plots for two runs. First one : A good initial guess (e.g., 0.8, 0.2) finds the global maximum. The Second: A bad initial guess (e.g., 0.2, 0.1) gets stuck in a suboptimal local maximum. |