Exploring the math behind VAE s from an undergrad student perspective
Variational Autoencoders (VAEs): A Complete Mathematical Derivation
Variational Autoencoders (VAEs) are generative models that combine probability theory with deep learning.
They learn a latent representation z for high-dimensional data x (e.g. images), and allow us to both encode and generate data.
1. The Generative Model
We assume the data x is generated from a latent variable z:
Sample latent code:
z∼p(z),p(z)=N(0,I)
Generate data from decoder:
x∼pθ(x∣z)
Thus, the joint distribution is
pθ(x,z)=pθ(x∣z)p(z).
The marginal likelihood of an observation is obtained by integrating over all latent variables:
pθ(x)=∫pθ(x∣z)p(z)dz.
2. The Intractability Problem
Computing pθ(x) requires evaluating a high-dimensional integral, which is usually intractable.
We are also interested in the posterior distribution of z:
pθ(z∣x)=pθ(x)pθ(x∣z)p(z).
But since pθ(x) is intractable, so is this posterior.
3. Variational Approximation
To address this, we introduce an approximate posterior qϕ(z∣x), parameterized by an encoder neural network.
The goal is to make qϕ(z∣x) close to the true posterior pθ(z∣x).
We measure closeness using the Kullback–Leibler divergence:
We can relate the ELBO to the KL divergence with the true posterior:
logpθ(x)=L(θ,ϕ;x)+KL(qϕ(z∣x)∥pθ(z∣x)).
Since KL divergence is always non-negative:
logpθ(x)≥L(θ,ϕ;x).
Thus, maximizing the ELBO makes qϕ(z∣x) approximate the true posterior.
6. Concrete Loss Function
Reconstruction term:
Ez∼qϕ(z∣x)[logpθ(x∣z)]
Encourages the decoder to reconstruct the data correctly.
In practice, this is a cross-entropy (for Bernoulli pixels) or mean squared error (for Gaussian outputs).
Regularization term (KL):
KL(qϕ(z∣x)∥p(z))
Encourages the approximate posterior to stay close to the Gaussian prior p(z)=N(0,I).
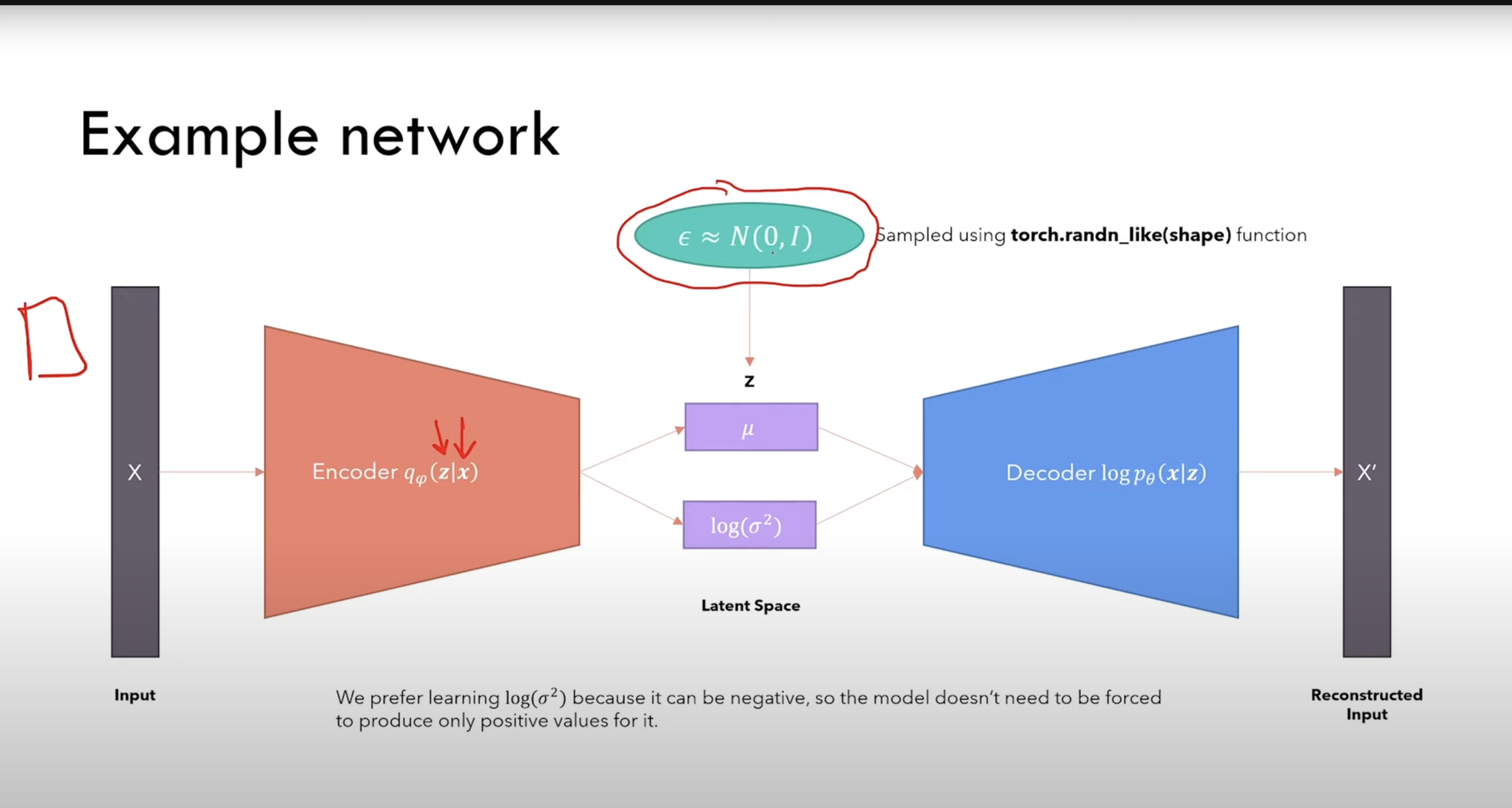
7. The Reparameterization Trick
To make gradients flow through random sampling, we reparameterize:
z∼qϕ(z∣x)=N(μϕ(x),σϕ2(x)I)
as
z=μϕ(x)+σϕ(x)⊙ϵ,ϵ∼N(0,I).
This allows backpropagation through z.
8. Final Training Objective
The training objective for a single data point x is:
This compact form highlights that VAEs balance reconstruction accuracy with latent space regularity, enabling smooth interpolation and generation of new data.